Quick Facts
- Category: Technology
- Published: 2026-05-03 08:30:43
- Cybersecurity Insiders Sentenced to Four Years for Role in BlackCat Ransomware Attacks
- DJI Osmo 360: 10 Key Features That Make It the Ultimate Action Camera for Adventurers
- DNA Folding Dynamics: How Active Genes Influence Neighbors Through Physical Changes
- NOAA Warns 'Record-Breaking' El Niño Transition Could Trigger Global Weather Chaos
- Apple Q2 2026 Earnings Breakdown: Revenue Hits $111.2B, Up 17%
Introduction
Large language models (LLMs) have become indispensable tools, yet their inner workings remain a black box. When a model outputs text in an unexpected language, loops into repetition, or refuses a harmless request, developers often lack the means to trace the cause back to specific internal computations. The newly released Qwen-Scope addresses this gap head-on.
Developed by the Qwen Team, Qwen-Scope is an open-source suite of sparse autoencoders (SAEs) trained on the Qwen3 and Qwen3.5 model families. The package includes 14 groups of SAE weights spanning seven model variants—five dense models and two mixture-of-experts (MoE) models. This release marks a significant step toward turning opaque neural activations into actionable insights for AI developers.
What Are Sparse Autoencoders?
A sparse autoencoder serves as a translation layer between raw neural network activations and human-interpretable concepts. When an LLM processes text, it generates high-dimensional hidden states—vectors containing thousands of numerical values that are difficult to analyze directly. An SAE learns to decompose these activations into a large dictionary of sparse latent features. For any given input, only a small subset of these features activates, and each such feature tends to correspond to a specific, understandable concept: a language, a writing style, or a safety-relevant behavior.
Technically, for each backbone model and each transformer layer within it, Qwen-Scope trains a separate SAE to reconstruct residual-stream activations using a sparse set of latent features. The SAE encoder maps every activation to an overcomplete latent representation, and a Top-k activation rule retains only the largest k latent activations for reconstruction. In this release, k is set to either 50 or 100. For dense backbone models, the SAE width scales to 16 times the model's hidden size; for MoE backbones, standard SAEs use a width of 32K (16× expansion), while wider SAEs up to 128K width (64× expansion) are also provided to capture finer-grained representation structures.
The result is a layer-wise feature dictionary for every transformer layer across all seven backbone variants. A notable technical detail: among the seven backbones, only Qwen3.5-27B uses the instruct variant for training its SAEs; the other six rely on their base model checkpoints.
Qwen-Scope Release Details
Model Variants Covered
- Dense models: Qwen3-1.7B, Qwen3-8B, Qwen3.5-2B, Qwen3.5-9B, Qwen3.5-27B
- Mixture-of-Experts (MoE) models: Qwen3-30B-A3B, Qwen3.5-35B-A3B
The SAE weights are organized into 14 groups, ensuring comprehensive coverage across model sizes and architectures.
Four Ways Qwen-Scope Changes the Development Workflow
The Qwen-Scope suite enables several practical applications that directly impact how developers build and debug LLM-based systems.
1. Inference-Time Steering
The most immediate application is inference-time steering—influencing model output without modifying any weights. The approach builds on a well-supported hypothesis: high-level behaviors are encoded as directions in the model's internal representation space. By adding or subtracting a feature direction from the residual stream during inference (using the formula h' ← h + αd, where h is the hidden state, d is the SAE feature direction, and α controls the strength), engineers can gently push the model toward—or away from—specific behaviors.
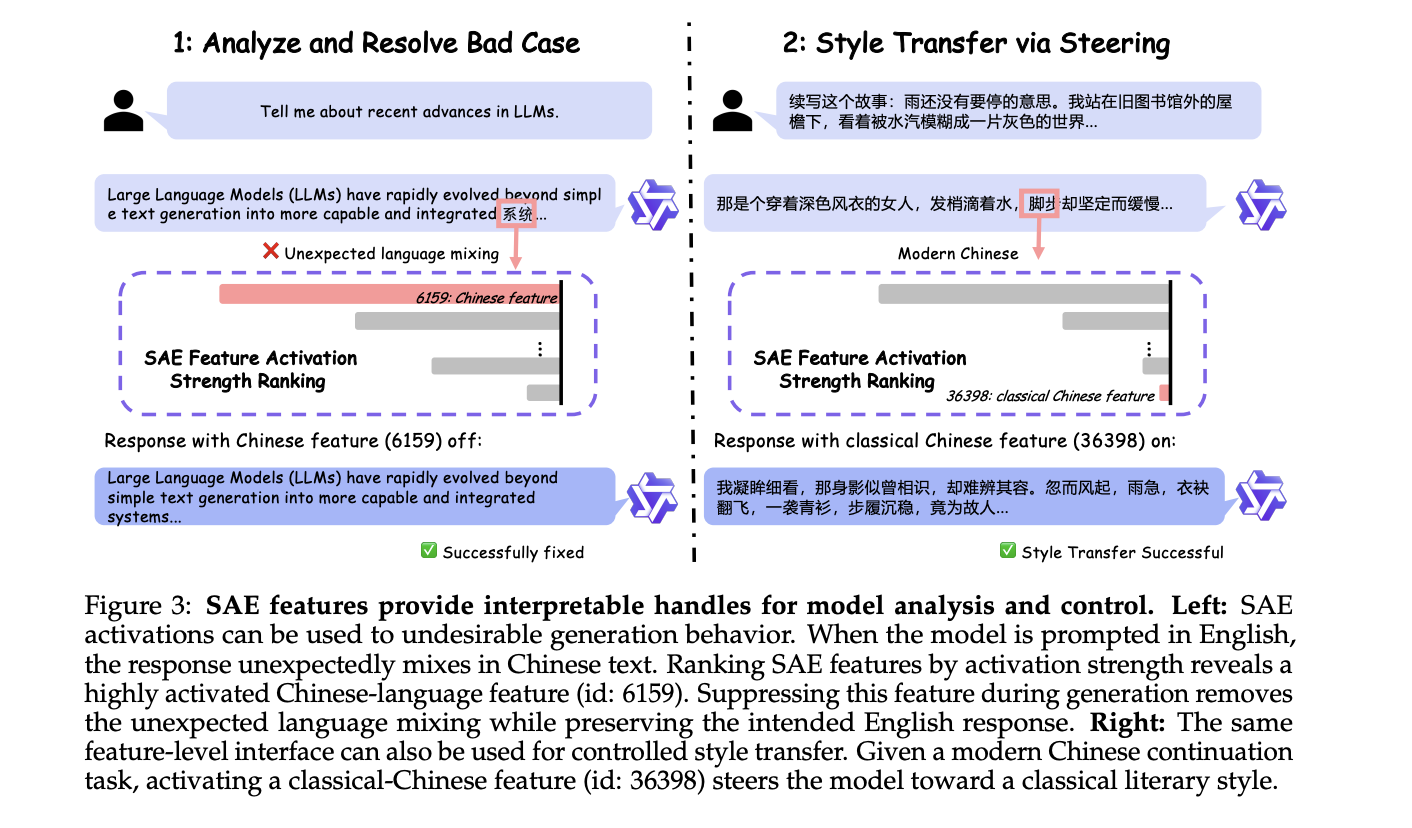
The research team demonstrated two case studies on Qwen3 models. In the first, a model prompted to generate text in a certain language was steered to avoid unwanted linguistic patterns. In the second, safety-related features were adjusted to reduce overly cautious refusals. These examples highlight how SAE-discovered features can be used to dynamically shape model behavior at runtime.
2. Debugging and Interpretability
Beyond steering, SAE features provide a powerful diagnostic tool. When a model exhibits a failure mode, developers can inspect which features are active in the relevant layers. This allows root-cause analysis at the level of internal computations, turning vague observations into specific, actionable insights.
3. Feature-Based Monitoring
By continuously monitoring feature activations, teams can detect drift in model behavior over time. For example, if a feature associated with a particular language becomes overly dominant, it may signal a distribution shift in the input data. This kind of monitoring can be integrated into CI/CD pipelines for LLM applications.
4. Custom Feature Editing
Advanced users can combine SAE features with projection techniques to create custom feature vectors. This enables targeted interventions—such as reducing the influence of a harmful concept while preserving overall model performance—without retraining the entire model.
Getting Started with Qwen-Scope
Qwen-Scope is released as an open-source toolkit, available for research and production use. Developers can download the SAE weights for their chosen backbone model and integrate them into existing inference pipelines. The package includes documentation and example code for inference-time steering and feature extraction.
For teams working with Qwen3 or Qwen3.5 models, Qwen-Scope offers a practical path from opaque activations to interpretable, controllable AI. The suite represents a significant step forward in making LLM internals not just observable, but actionable.