What Is Tokenization Drift?
Large language models (LLMs) process text by first converting it into numerical token IDs. This step, known as tokenization, is far from uniform: tiny variations in spacing, line breaks, or punctuation can produce completely different token sequences. When such surface-level changes push your input into a different region of token space, the model's behavior can shift unpredictably. This phenomenon is called tokenization drift — a subtle but powerful source of instability that can degrade model performance even when your data, pipeline, and logic remain unchanged.
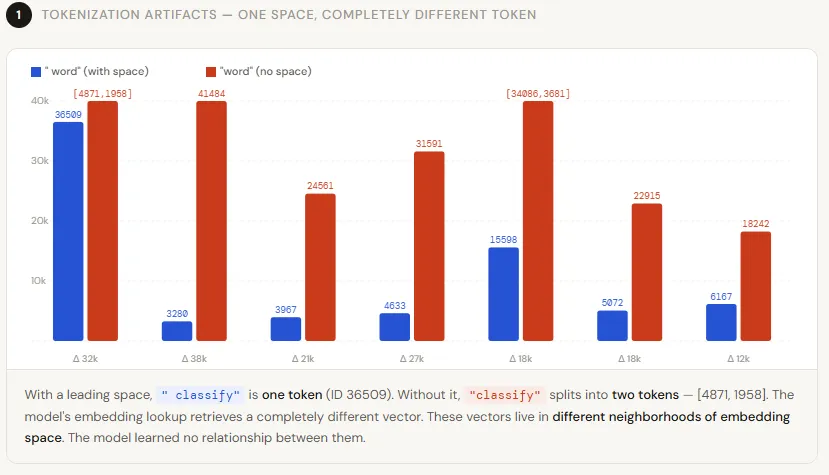
Why Does It Matter?
Tokenization drift doesn't just alter token IDs. During instruction tuning, models learn not only tasks but also the structural patterns in which those tasks are presented — specific separators, prefixes, and formatting conventions. When your prompt deviates from these learned patterns, you are essentially operating outside the model’s familiar distribution. The result is not confusion, but a model doing its best on inputs it was never optimized to handle. This can lead to inconsistent outputs, lower accuracy, and unexpected errors in production.
A Concrete Demonstration
To see tokenization drift in action, consider an experiment using the GPT-2 tokenizer — a Byte-Pair Encoding scheme identical to that used by GPT-4, LLaMA, and Mistral. Seven common words were tested in two forms: once with a leading space and once without. The results are striking. Not a single pair produces the same token ID. Every word is treated as completely different depending on whether it has a leading space.
The Space-Prefix Artifact
This space-prefix artifact is a hallmark of modern tokenizers. They treat words with and without a leading space as distinct tokens, which means that simply adding or omitting a space before a word can shift the entire token sequence for your prompt. The model sees a different input altogether.
Variable Token Lengths
Even more interesting, some words without a leading space don’t map to a single token at all. For example, “classify” without a space becomes two tokens, while “ classify” with a space is a single token. This means the model doesn’t just see a different ID — it sees a different sequence length, which shifts how attention is computed for everything that follows. Such changes ripple through the entire model, affecting predictions downstream.
Measuring Drift
To quantify tokenization drift, you can build a simple metric that compares token sequences between a reference prompt (e.g., the one used during training) and a new prompt. By counting the number of token mismatches or computing a distance measure in token space, you can detect when drift is significant. This metric serves as an early warning system, flagging prompts that may trigger unexpected behavior.
Mitigating Drift
Once you can measure drift, the next step is to fix it. A lightweight optimization loop can be implemented to search for prompt formats that minimize drift while preserving the intended meaning. This involves systematically adjusting spacing, punctuation, and other formatting elements, evaluating the drift metric, and selecting the format that keeps token sequences closest to the model’s training distribution. The result is a reproducible, reliable prompt that reduces variability and improves consistency.
Practical Tips for Reducing Drift
- Use consistent spacing — always include a leading space before words when the training data did.
- Standardize separators (e.g., always use colons or newlines in the same way).
- Avoid unnecessary punctuation that might break tokens.
- Test your prompts against a reference token sequence to catch drift early.
Conclusion
Tokenization drift is a hidden but critical factor in LLM performance. By understanding how subtle formatting changes affect token IDs and sequence lengths, you can take proactive steps to keep your prompts within the model’s optimized distribution. Measuring drift and applying simple formatting optimizations will lead to more stable, predictable model outputs — without changing your data or logic.